In this example the parameter clearance (CL) has two covariates effects:
A continuous covariate power model of body weight (Weight) with a reference value of 70 (kg)
A continuous covariate emax/hill maturation model as a function of Age.
The ηCL denotes the individual deviations from the population (random effects) which assumes that the population CL is log normally distributed.
Common software will estimate the fixed effects, random effects variances and provide the associated standard errors. For example we would get POPCL = 42 ± 1.73 L/h, the weight power effect = 1.0078 ± 0.17 and age maturation Age50 = 4.84 ± 2.90 years. What would be the Cl for a 3 years old 14 kg kid? 42(14/70)^1.0078(3/(3+4.84)) = 3.17 L/h. What would be its standard error?
Also, we often want to report the CV% of the log normal distribution expressed as:
\[CV(\%)=\sqrt{\left(e^{\omega^2}-1\right)}\] Again, what would be the standard error of the CV%?
The delta method is a statistical technique to approximate the standard error of a function of an estimator, such as a ratio or the log odds ratio or the inverse logit of a constrained parameter, using a first-order Taylor series expansion. It’s especially useful when the function involves more than one parameter and/or the equation is complex such as there is no straightforward analytically computed solution. It relies on the original variable(s), the function form and the partial derivative of the function with respect to the parameters and the variance covariance matrix of the involved parameters. It has been used in multiple fields, including pharmacometrics, that the delta method matches the gold standard (simulation with uncertainty) even with longitudinal model based meta-analysis (MBMA) nonlinear models. Also, in this important paper from the FDA entitled Clarification on Precision Criteria to Derive Sample Size When Designing Pediatric Pharmacokinetic Studies R code to compute the delta method for derived variables was provided in APPENDIX 3. R code for delta method to estimate standard error for a derived variable
\[log(CL) = \color{blue}{3.7421} + \color{blue}{1.0078}\times log\left( \frac { \color{green}{Weight}} {70}\right)+log\left(\color{green}{Age}/(\color{green}{Age}+4.8422)\right)\] Note that the log of the equation above was estimated and used:
# Assume covariate model CL=theta1*(wt/70)** theta2*age/(age+theta3) and# Log of CL was modeled as LCL=thetap1+theta2*log(wt/70)+log(age/(age+theta3))#input parameter estimates thetap1=3.7421 theta2=1.0078 theta3=4.8422#input variance-covariance matrix for the 3 parametersabove covp3=matrix(c(0.29810, 0.05782, 1.27120,0.05782, 0.02921, 0.02073,1.27120, 0.02073, 8.42210),nrow=3, byrow=T)#define the weight and age combination for SE estima-tion wt=14 age=3#define covariate model in R f <-function(x,y,z) x + y*log(wt/70) +log(age/(age+z)) df<-deriv(body(f), c("x","y","z")) x=thetap1 y=theta2 z=theta3 out=eval(df) dfout=attr(out,"gradient") varlcl=dfout%*%covp3%*%t(dfout)SElcl=sqrt(varlcl)SElcl
[,1]
[1,] 0.09436884
The code above works, but it is easier to use the R package msm which has a streamlined general deltamethod function of which I have a copy in my own package coveffectsplot. The only difference in mine is explicitly adding the evaluation environment which was necessary for the function to properly work in an R Shiny App. The deltamethod function source code:
deltamethod <-function (g, mean, cov, ses =TRUE, envir =parent.frame()) { cov <-as.matrix(cov) n <-length(mean)if (!is.list(g)) g <-list(g)if ((dim(cov)[1] != n) || (dim(cov)[2] != n)) stop(paste("Covariances should be a ", n, " by ", n, " matrix")) syms <-paste("x", 1:n, sep ="")for (i in1:n) assign(syms[i], mean[i]) gdashmu <-t(sapply(g, function(form) {as.numeric(attr(eval(deriv(form, syms)), "gradient")) })) new.covar <- gdashmu %*% cov %*%t(gdashmu)if (ses) { new.se <-sqrt(diag(new.covar)) new.se }else new.covar}
I load coveffectsplot and use the deltamethod function to recompute SElcl exactly matching the result above note how the function should refer to the parameters as x1, x2, …, etc.
Back to the random effect variance expressed as CV% standard error we can use the same code and function to compute a standard error for a transformation of the original estimated variance:
omegaCL<-0.42 covOMEGA=matrix( c(0.2),nrow=1, byrow=T)sqrt(exp(omegaCL)-1) # formula for CV of a log normal
[1] 0.7224691
The CV% is computed to be ~72.2 % with a standard error of: 0.4710526
Another approach, albeit more time consuming, is to simulate the distribution using enough n samples and then compute the CV% using its formula: sd(x)/mean(x) which will exactly match the analytical formula for this relatively simple case:
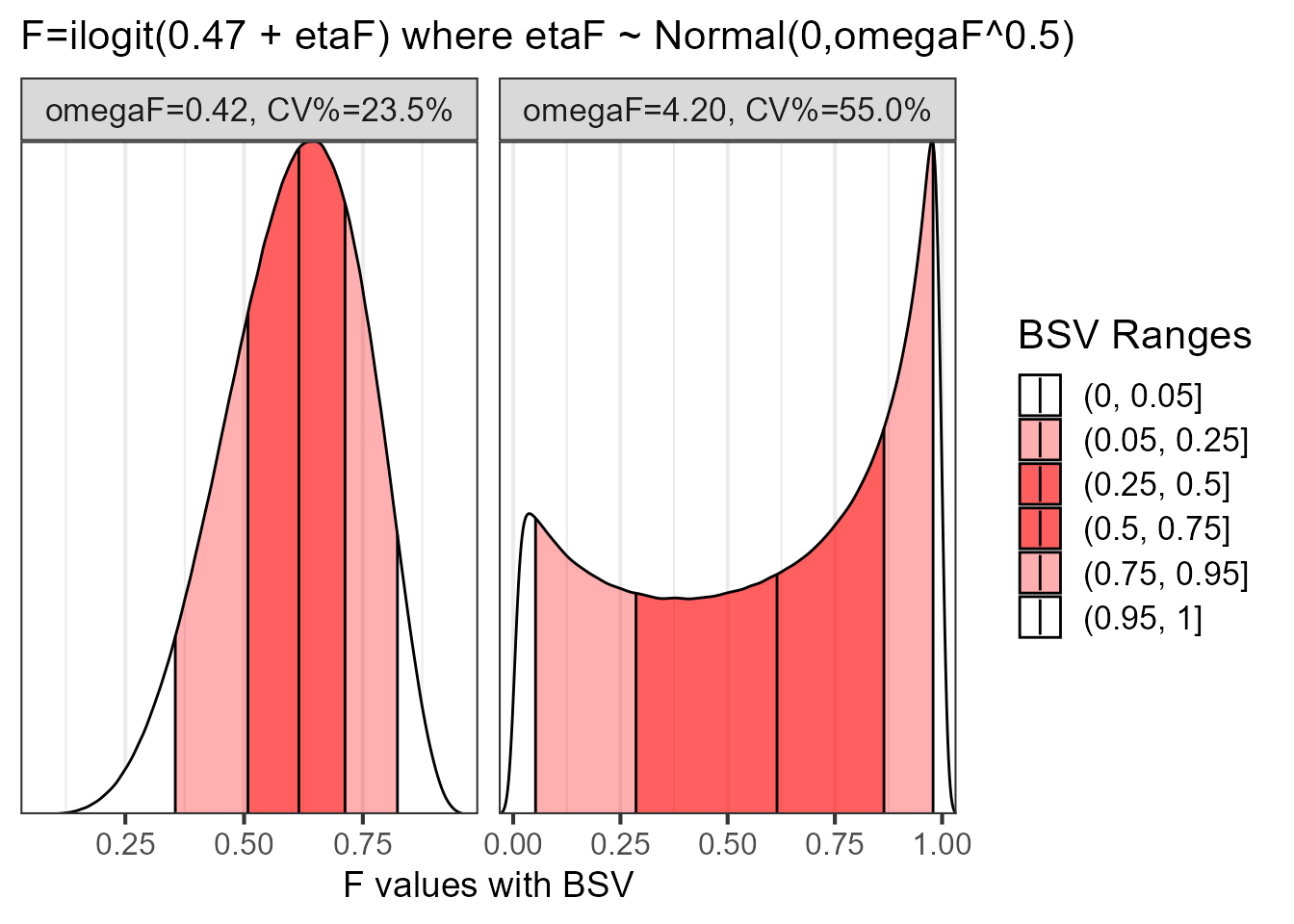
What if we have a more complex random effect model? Say an inverse logit transformation to constrain a parameter like bioavailbility between 0 and 1? Let us explore it with simulation !
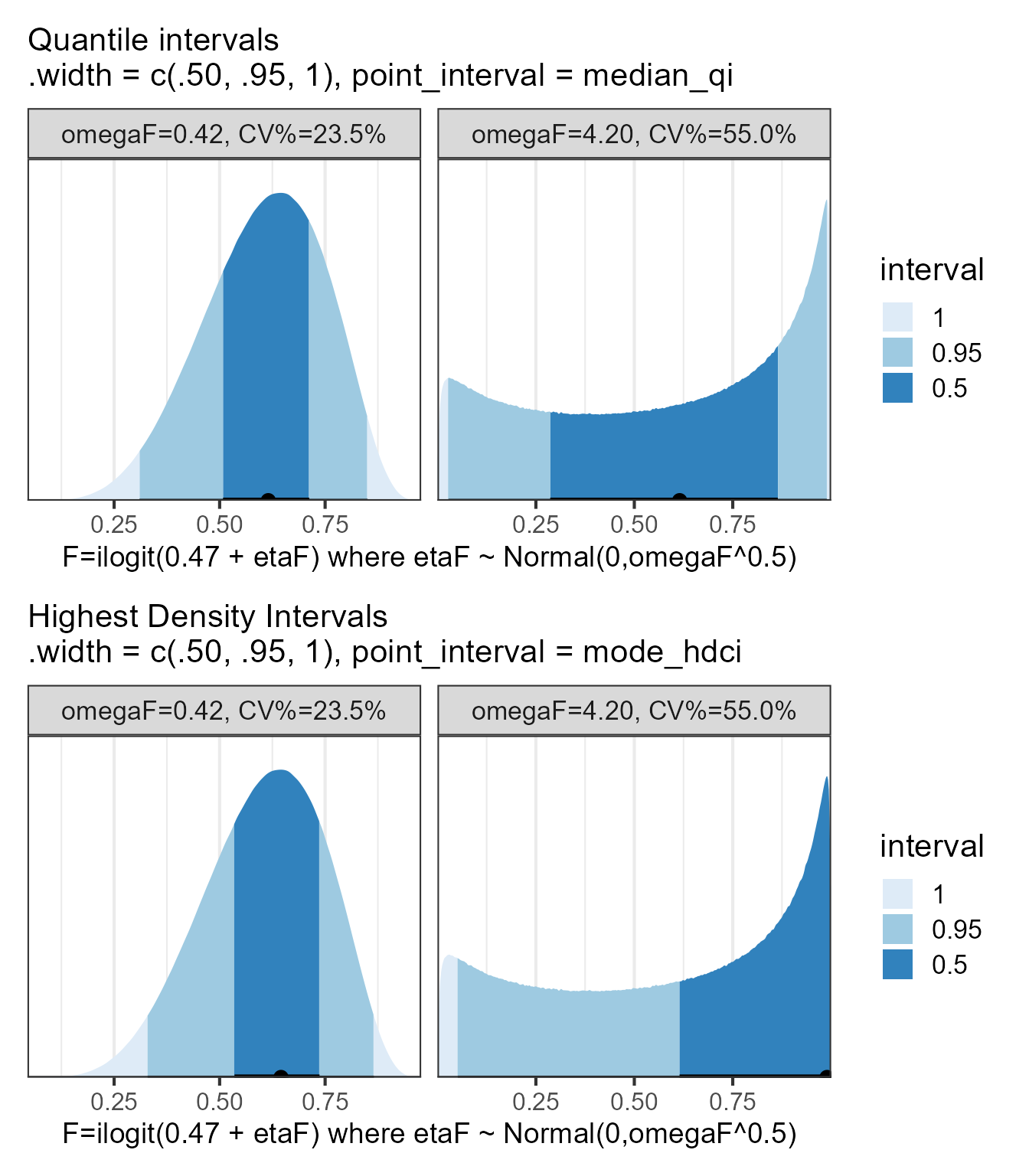
We can now see that when omegaF is 0.42 the distribution is a bit skewed with one mode while when the omegaF is 4.2 the distribution becomes multi-modal with a “weird” concentration of mass at 0 and 1. How representative is to “summarize” such a distribution with a CV%? isn’t it more useful to show the full distribution? This would help us in understanding the distribution shape and where will 50 or 90% of my patients be on the F scale. Another possible interval for highly skewed distribution are the highest density intervals which I will illustrate next using ggdist:
When a distribution is asymmetrical, multimodal and/or with an important mass at the boundaries the quantile, the highest density and the highest density continuous intervals will significantly differ. I highly recommend to plot the data and to provide multiple interval types for such distributions.
In this post I have shown several examples/applications of the delta method to compute confidence intervals for a model statistic of interest that can be a function of one or multiple model parameters. I have also covered how to compute intervals around random effects distributions via simulations arguing that a single stat, such as CV%, can be misleading for non-symmetrical and/or multi-modal distributions using an inverse logit transformation of bioavailibility (F) as an example.